一种加速构建多组元材料热力学数据库的方法、存储介质
本发明涉及金属材料的计算热力学领域,尤其是涉及一种具体涉及一种耦合第一性原理计算的主动学习框架,加速构建多组元材料热力学数据库的方法。
背景技术:
1、合金和化合物的热力学数据,如形成焓(也称为标准形成热),在多种应用中发挥着重要作用,例如在相图计算和材料设计中,在探索可用于先进燃煤电厂、热交换器、过滤器和涡轮机的高熔点新材料中等等。在基于相的热力学建模与平衡计算相结合的calculation of phase diagrams(calphad)方法中,形成焓通常作为吉布斯自由能的一部分,比如端际化合物(简称端际组员)的吉布斯自由能。而对每种相的吉布斯自由能进行细致的量化和分析,有助于直观地了解不同相的形成和相变过程。这种理解是有效和高效材料设计策略的关键支柱。通常采用密度泛函理论(dft)计算来精确计算端际化合物的形成能,但不可避免地会导致巨大的计算成本,因为对于含有约10种不同元素的实际合金来说,端际化合物的数量可达10^5个。这为在实践中应用机器学习(ml)提供了一个独特的机会。
2、当前将机器学习用于化合物能量预测的研究仅专注于无磁的化合物,比如来自法国巴黎索邦大学的jean-claude crivello对sigma相端际组员形成的研究工作。这些工作中研究合金化合物时,使用的第一性原理计算并未考虑磁性的贡献,这很大程度影响了模型预测的可靠性。其次,比如来自美国西北大学logan ward团队预测无机化合物形成能的工作,这些工作中使用的机器学习模型都没有自我训练、自我提升的过程,往往只经过一次训练就投入应用,这显然无法满足大数据时代对机器学习模型的需求。我们的工作及考虑了合金中磁性对形成能的贡献,又可以在数据库不断增长的过程中,不断迭代机器学习模型,提高模型精度和泛化能力。
技术实现思路
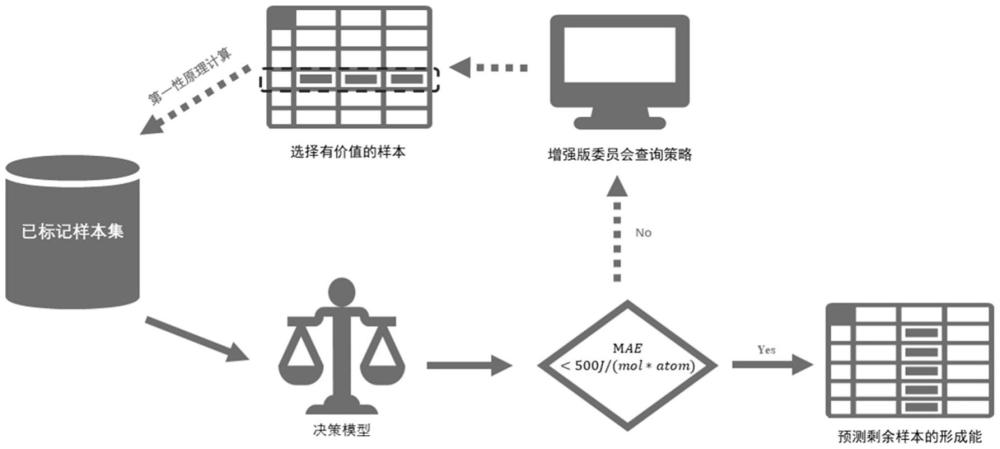
1、本发明的目的在于克服第一性原理计算在建立热力学数据库时的盲目性,提供一种耦合第一性原理计算的主动学习框架,加速构建多组元材料热力学数据库的方法。通过给定若干初始化合物形成能样本,就能实现材料热力学数据库构建的自动化流程,操作简单快捷。
2、本发明的目的可以通过以下技术方案来实现:
3、本发明第一方面提供一种加速构建多组元材料热力学数据库的方法,包括以下步骤:
4、s1:在迭代开始前,将体系所有端际化合物划分为三个子集:已标记样本池、未标记样本池和测试集,其中已标记样本池和测试集的数据形成能通过第一性原理计算获得,未标记样本池由未进行计算的端际化合物组成;
5、s2:基于已标记样本池构建决策模型,并在测试集上观察预测精度,如果预测精度达到预定标准,则停止迭代,否则基于增强委员会策略,选择未标记样本进行计算优化;
6、s3:使用集成学习模型对所有未标记样本进行形成能和不确定性分布的预测,并将结果用于建立体系热力学数据库。
7、进一步地,s1中,具体包括:
8、s1-1:假设多组元a体系需要计算n个端际化合物的形成能,首先利用vasp软件计算数量为l和t的端际化合物的形成能,其中,l样本集合为初始已标记样本集,t样本集合为测试集,剩余n-(l+t)个样本为未标记样本集合u;
9、s1-2:对n个样本进行数据预处理,构建11个宏观尺度特征;
10、s1-3:对n个样本进行数据预处理,构建110个微观尺度特征。
11、进一步地,s1-1中,每个端际化合物都使用以下公式进行计算:
12、
13、其中,n表示每个端际组员中元素的数量,而k表示不同的元素性质,ci和分别对应于第i个元素的成分和指定元素性质。
14、进一步地,s1-3中,所述微观尺度特征分为两个部分:
15、第一部分为e*p个特征,其中e表示化合物的wyckoff位置中的不等效位点数量,p是来自表1的11个元素性质,利用one-hot编码化合物的wyckoff位置;
16、第二部分为e*p个特征,描述每个等效位点的局部环境特征,使用voronoi技术计算晶胞中每个原子周围最近邻voronoi多面体来权重周围原子对中心原子的能量贡献,由以下公式计算得到:
17、
18、其中pi表示第i个中心原子的性质,ph表示中心原子i最近邻的第n个原子的性质,an表示中心原子i最近邻的第n个原子对应的voronoi多面体的面积。
19、进一步地,s2中,具体包括:
20、s2-1:以经过验证的支持向量机算法作为决策模型,在l数据集上进行建模;所述支持向量机回归算法使用基于python语言的sciki-learn库,使用网格搜索和10-折交叉验证方法筛选最佳模型参数和模型d;
21、s2-2:计算决策模型d在测试集t上的平均绝对误差(mae),公式如下所示:
22、
23、其中是决策模型d在第i个测试集样本的预测值,yi表示第i个测试集样本的真实值,n表示测试集样本的总数;
24、如果指标mae小于阈值,则停止迭代,否则基于增强委员会策略,选择未标记样本进行计算优化。
25、进一步地,所述基于增强委员会策略,选择未标记样本进行计算优化包括:
26、从未标记样本池中选择部分端际化合物作为候选者,随后对这些候选者进行第一性原理计算,计算完成以后加入已标记样本池,重复s2,直到决策模型在测试集上达到预期精度,停止迭代。
27、进一步地,所述基于增强委员会策略,选择未标记样本进行计算优化具体包括:
28、a-1:基于已标记样本集合l,使用bootstrap采样得到5个独立的训练集,用于后续5个委员会模型的训练;
29、a-2:使用支持向量机算法作为基模型,在5个独立训练集上训练5个委员会模型,使用网格搜索和10-折交叉验证方法筛选最佳模型参数和模型;
30、a-3:使用增强版委员会策略(enhanced-query-by-committee,eqbc),计算未标记样本集u上的不确定性指标;
31、a-4:从未标记样本池中选择不确定指标最大的若干候选者,随后对这些候选者进行第一性原理计算,计算完成以后加入已标记样本池l中。
32、进一步地,所述不确定性指标的计算公式如下:
33、
34、其中m表示未标记样本集u中第m个样本,表示该样本的不确定性,p表示委员会模型的数量,表示该样本在第p个委员会模型上的预测值,表示第m个样本在p个委员会模型上预测的均值。
35、进一步地,s3中,具体包括:
36、s3-1:使用上一轮迭代中训练完成的p个委员会模型,输出剩余未标记样本的平均绝对百分比误差(mape)估计的分布,公式如下:
37、
38、其中yi表示第i个实际值,表示第i个的预测值,n表示所有数据点;
39、s3-2:将决策模型d和上一轮迭代训练完成的p个委员会模型,共(1+p)个模型组成集成学习模型,使用堆叠的集成方式,使用网格搜索和10-折交叉验证方法筛选最佳集成学习模型m的超参数,模型m的预测过程如下所示:
40、
41、其中m表示集成的模型数量,mm(x)表示第m个模型对样本x的预测值,mmeta表示元模型,以组合特征h(x)为输入,输出最终的预测结果;
42、s3-3:利用集成学习模型m输出所有未标记样本的形成能,并给出样本的不确定分分布图,用于体系热力学数据库的建立。
43、本发明第二方面提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令的存储介质在由计算机处理器执行时,用于执行如上述的加速构建多组元材料热力学数据库的方法。
44、与现有技术相比,本发明具有以下技术优势:
45、1.本发明方法克服传统第一性原理计算的盲目性,节约资源和时间,将主动学习框架耦合第一性原理计算,给定初始的样本集合,就能自动化实现材料热力学数据库的建立。
46、2.本发明方法在整个过程中不涉及实验和不使用化学用品,不产生化学污染,符合绿色环保理念;且操作简单,成本低,易于实现,适合推广应用。
47、3.本发明方法通过机器学习模型的计算结果可以提前预测材料的形成能,挑选不确定性较低的样本进行热力学建模,可以节约建模时间和资源,提高建模的效率,起指导作用,避免盲目性。
48、4.给出了兼顾宏观和微观尺度的多尺度特征集,能够更加直观的展示不同尺度特征对化合物形成能的贡献。
49、5.本发明方法在机器学习建模过程中考虑了磁性对能量的贡献,并通过第一性原理计算了部分纯组元的磁矩,保证了建模的合理性,又增加了模型的准确度。
50、6.本发明给出了所有未计算样本的不确定性估计,增加了机器学习模型的可解释性。
技术研发人员:查炀,鲁晓刚
技术所有人:上海大学
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除