脑卒中后谵妄风险预测模型的构建方法
本发明涉及大数据处理,具体为脑卒中后谵妄风险预测模型的构建方法。
背景技术:
1、随着现代医疗科技的发展,个性化医学成为一个新的趋势,特别是在脑卒中等神经系统疾病的康复过程中,个性化风险评估显得尤为重要。针对不同患者的康复效果,风险预测模型能够提前识别高危患者,进行个性化管理。
2、中国专利申请号cn202310055764.x的发明中,公开了一种癌症复发风险预测模型构建方法,通过整合单细胞和全转录组测序数据集识别影响免疫治疗响应的与预后相关的基因,并构建预后风险模型,有利于不同肿瘤诊断生物标志物的应用手册制定与靶向药物的设计,为肿瘤的临床诊断与治疗提供新的思路。
3、由此可知,尽管已有诸多的风险预测模型可以使用,诸多的脑卒中后谵妄风险评估模型在临床中应用,但大多数模型仍然采用固定的风险因素权重,缺乏针对个体差异的调整。这种一刀切的方法,虽然能够给出大致的风险评估,但难以考虑到不同患者在年龄、病史等个体特征方面的差异。这些模型通常依赖于通用数据集和固定的关联规则,忽视了患者独特的病史和生理状态对预测结果的影响,导致了模型预测的精确度不足。例如,年龄较大的患者与较年轻的患者在脑卒中后的恢复情况上有明显差异,然而现有的许多模型对这些差异并没有作出充分的反映。
技术实现思路
1、针对现有技术的不足,本发明提供了脑卒中后谵妄风险预测模型的构建方法,解决了背景技术中提到的问题。
2、为实现以上目的,本发明通过以下技术方案予以实现:一种脑卒中后谵妄风险预测模型的构建方法,包括以下步骤:
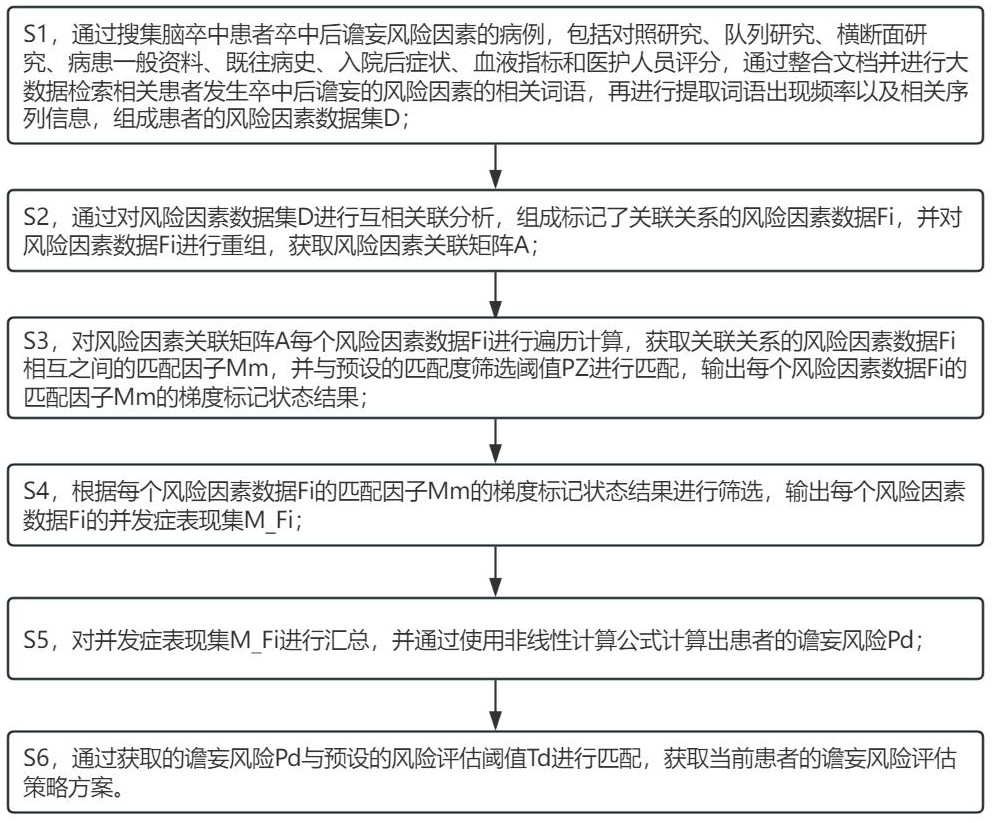
3、s1,通过搜集脑卒中患者卒中后谵妄风险因素的病例,包括对照研究、队列研究、横断面研究、病患一般资料、既往病史、入院后症状、血液指标和医护人员评分,通过整合文档并进行大数据检索相关患者发生卒中后谵妄的风险因素的相关词语,再进行提取词语出现频率以及相关序列信息,组成患者的风险因素数据集d;
4、s2,通过对风险因素数据集d进行互相关联分析,组成标记了关联关系的风险因素数据fi,并对风险因素数据fi进行重组,获取风险因素关联矩阵a;
5、s3,对风险因素关联矩阵a每个风险因素数据fi进行遍历计算,获取关联关系的风险因素数据fi相互之间的匹配因子mm,并与预设的匹配度筛选阈值pz进行匹配,输出每个风险因素数据fi的匹配因子mm的梯度标记状态结果;
6、s4,根据每个风险因素数据fi的匹配因子mm的梯度标记状态结果进行筛选,输出每个风险因素数据fi的并发症表现集m_fi;
7、s5,对并发症表现集m_fi进行汇总,并通过使用非线性计算公式计算出患者的谵妄风险pd;
8、s6,通过获取的谵妄风险pd与预设的风险评估阈值td进行匹配,获取当前患者的谵妄风险评估策略方案。
9、优选的,所述s1包括s11、s12和s13;
10、s11,通过医院的神经内科与神经外科科室中符合纳入标准的脑卒中患者作为研究对象,并对收集的数据信息进行搜集脑卒中患者卒中后谵妄风险因素的研究信息,包括对照研究、队列研究和横断面研究,并结合病例信息收集一般资料、既往病史、入院后症状、血液指标和医护人员评分,组成初步检索的初始患者数据集draw={p1,p2,...,pn},其中p1至pn表示病例患者1至病例患者n。
11、优选的,s12,对获取初始患者数据集draw进行提取与谵妄风险相关的关键词语w,并对关键词语w的出现频率进行统计,通过大数据处理技术,计算关键词语w在病例患者数据中的频率fi,并进行标记相关的关键词出现的序列信息s,关键词语在患者的病例信息中的位置和顺序,组成关键词频率集合q={f1,f2,...,fi};
12、所述频率fi通过以下计算公式获取:;式中,fi表示频率,具体表示关键词在初始患者数据集draw中出现的频率,n表示初始患者数据集draw的长度,具体表示包括的病例患者总数,wm表示卒中后谵妄风险相关的第m个关键词语wm,具体为m表示关键词语w的下标信息,通过wm的组合确定了第m个关键词语wm,进而通过wm进行定位到第m个关键词语wm,m表示关键词语总数,具体通过统计预设的检索关键词语总数获取,pj表示初始患者数据集draw中第j个病例患者,其中,检索关键词具体包括性别、年龄、既往卒中、既往认知障碍、高血压、高血脂、糖尿病、卒中类型、吸烟、饮酒、心房纤颤、缺血性心脏病、心功能衰竭、感染、插管、中细胞比率、淋巴细胞比率、发烧、尿失禁、视野缺损、adl生活能力评分、nihss评分、失语和吞咽困难关键词。
13、优选的,s13,对关键词频率集合q进行提取与风险因素相关的序列信息s,同步将第1至m个关键词语及其出现的序列信息s组合成序列特征,并整合成风险因素数据集d;
14、所述风险因素数据集d通过以下整合方式获取:;式中,sk表示第m个关键词语wm的第k个序列信息。
15、优选的,所述s2包括s21和s22;
16、s21,根据获取的风险因素数据集d对卒中后谵妄风险相关的第m个关键词语wm和第p个关键词语wp进行基于序列信息s的关联分析,获取第m个关键词语wm和第p个关键词语wp在不同序列信息s位置出现模式之间的关联性,生成关联标记rmp,组成标记了关联关系的风险因素数据fi={(wm,wp,rmp)};
17、所述关联标记rmp通过以下计算公式获取:;式中,rmp表示关联标记,具体表示第m个关键词语与第p个关键词语之间的关联强度,nm表示第m个关键词语出现的总数,k表示第m个关键词语wm出现在总数nm中的第k次,np表示第p个关键词语出现的总数,l表示第p个关键词语wp出现在总数np中的第l次,表示关键词语wm的平均序列位置,表示关键词语wp的平均序列位置,swmk表示第k次出现的关键词语wm的序列信息,swpl表示第l次出现的关键词语wp的序列信息。
18、优选的,s22,根据生成的标记有关联关系的风险因素数据fi进行重组第m个关键词语wm与第p个关键词语wp的关联信息,构建出关联词语的关联矩阵a,具体表示第m个关键词语wm与第p个关键词语wp的互相关联程度;
19、所述关联矩阵a具体通过以下方式组成:;式中,关联矩阵a中每个矩阵元素rmp表示关键词语wm和关键词语wp之间的关联强度,对角线元素rmm=1表示自关联,其中,第m个关键词语wm和第p个关键词语wp之间可以是相邻的,也可以不是相邻的甚至可以隔开多个位置。
20、优选的,所述匹配因子mm通过以下计算公式获取:;式中,mm表示匹配因子,具体表示第m个关键词语wm的匹配因子,amp表示关联矩阵a中的元素,具体表示第m个关键词语和第p个关键词语之间的关联强度,pp表示第p个关键词语在关键词频率集合q中的频率值;
21、其中,匹配因子mm通过遍历关联矩阵a的第m行来计算,即计算关键词语wm与所有其他关键词wp之间的关联强度,并根据这些关联强度对每个关键词语的值进行加权;
22、所述每个风险因素数据fi的匹配因子mm的梯度标记状态结果通过以下匹配方式获取:;当匹配因子mm≥匹配度筛选阈值pz时,获取梯度标记状态结果为第一梯度标记,以及label=1,表示风险因素数据fi中第m个关键词语wm与第p个关键词语wp之间的匹配关系标记为1,具体表示第m个关键词语wm与第p个关键词语wp为第一梯度的关联度;
23、当匹配因子mm<匹配度筛选阈值pz时,获取梯度标记状态结果为第二梯度标记,以及label=2,表示风险因素数据fi中第m个关键词语wm与第p个关键词语wp之间的匹配关系标记为2,具体表示第m个关键词语wm与第p个关键词语wp为第二梯度的关联度。
24、优选的,所述并发症表现集m_fi基于梯度标记状态结果,进行整合风险因素数据fi获取并发症表现集m_fi,具体通过筛选第m个关键词语wm与第p个关键词语wp为第一梯度的关联度的第p个关键词语wp,进而组成只有第一梯度的关联度的风险因素数据fi的并发症表现集m_fi。
25、优选的,通过使用非线性计算公式计算出患者的谵妄风险pd,其中患者通过s1至s4步骤获取一般资料、既往病史、入院后症状、血液指标和医护人员评分信息,组成患者的体征数据集p,并将体征数据集p与并发症表现集m_fi进行匹配,获取出现的并发症总数量nmatch,并与并发症表现集m_fi的长度值mfc进行计算,获取谵妄风险pd;
26、所述谵妄风险pd通过计算公式获取。
27、优选的,所述当前患者的谵妄风险评估策略方案通过以下匹配方式获取:
28、当谵妄风险pd<风险评估阈值td时,获取当前患者的谵妄风险评估为不存在风险策略;
29、当谵妄风险pd≥风险评估阈值td时,获取当前患者的谵妄风险评估为存在谵妄风险策略,对当前患者病例信息进行标记和保留,并发送通知至相关医生进行会诊;
30、当谵妄风险pd≥风险评估阈值td两倍时,获取当前患者的谵妄风险策略评估为谵妄预警风险策略,对当前患者病例信息进行标记和保留,并发送谵妄预警风险策略通知至相关医生进行处理。
31、本发明提供了脑卒中后谵妄风险预测模型的构建方法,具备以下有益效果:
32、通过s1至s6步骤,充分利用了患者的个体化数据,提升了风险预测的精确性,解决了传统模型中一刀切问题所导致的不足,实现了从数据采集、关联分析到风险评估的全过程。首先,通过整合不同类型的研究和患者的个体数据,建立了全面的风险因素数据集d,涵盖了病患一般资料、既往病史、入院后症状等关键信息,这种多维度的数据采集方式避免了对患者个体特征的忽视,解决了现有模型中无法精准适配个体差异的缺陷。接着,通过风险因素关联矩阵a与匹配因子mm的计算,确保了不同症状和风险因素之间的关联被准确捕捉和分析,特别是通过筛选出梯度标记状态,进一步增强了模型的预测灵活性和准确性。将并发症表现集m_fi与患者数据进行匹配,计算出个性化的谵妄风险pd,通过与预设的风险评估阈值td进行对比,生成个性化的风险评估策略方案,这一过程确保了不同患者的风险评估更具针对性,避免了传统模型中因忽视个体化差异而导致的误判及延误。
33、通过将符合纳入标准的患者数据进行整合,生成初始患者数据集draw,涵盖对照研究、队列研究、横断面研究等多种研究数据,这为后续的谵妄风险关键词提取提供了扎实的基础。对初始患者数据集draw进行详细分析,提取与谵妄风险相关的关键词语w,并计算出每个关键词的出现频率fi以及关键词在病例信息中的序列信息s,这使得该方法不仅能够捕捉到关键词的整体频率,还能够识别其在不同患者病例中的具体分布情况,形成关键词频率集合q。最后,通过将关键词语及其序列信息s整合为风险因素数据集d,能够有效地保留和提炼出患者数据中的时序特征和关联模式,从而使风险评估模型能够对每个患者的个性化风险因素进行准确分析。该过程的特殊优势在于,能够通过引入患者病例中的时序和关联特征,进一步细化了风险评估,提升了模型的灵活性与动态预测能力。
34、利用风险因素数据集d,对卒中后谵妄相关的关键词语进行基于序列信息的关联分析,不仅提取出了关键词语wm和关键词语wp之间的关联关系,还通过计算关联标记rmp,捕捉了这些关键词在不同位置的出现模式和相互关系。这种基于序列信息的关联分析可以识别出风险因素的时序关联特征,生成的关联标记rmp能够为后续的模型优化提供更为准确的关联信息。通过关联标记rmp重组风险因素数据,构建了关键词语之间的关联矩阵a,细化了每个关键词之间的关联强度,并通过关联矩阵的遍历计算,生成每个风险因素数据的匹配因子mm。通过对匹配因子mm的梯度标记状态的计算,风险因素被准确分为第一梯度和第二梯度,确保模型在面对不同风险因素时能够动态调整其评估权重。这种双层梯度标记的机制特别适合捕捉复杂的风险因素关联,从而使模型在个性化分析中更加敏感和精准,避免了传统方法中因关联处理不当而导致的评估失误。
35、通过整合并发症表现集m_fi与患者的体征数据集p,结合非线性计算公式精准评估了患者的谵妄风险pd,显著提升了谵妄风险预测的灵敏度和及时性。不同于传统的单一风险评估,通过筛选出第一梯度关联度的关键词语wp,使并发症表现集m_fi更具针对性,与患者的个体体征数据p进行动态匹配,获取具体的并发症数量nmatch,并结合并发症表现集m_fi的长度值mfc来准确计算出谵妄风险pd。此过程中,模型不仅能够区分不同风险层级,还通过对谵妄风险pd与风险评估阈值td的匹配,智能化地划分患者的风险等级,并根据不同风险等级自动生成相应的评估策略,包括不存在风险、存在风险以及谵妄预警风险策略。这种分层策略评估机制的独特优势在于,不仅能够及时识别出高风险患者,并且在谵妄风险pd显著高于阈值时触发预警机制,通过信息标记与医生的实时通知实现精准和快速的干预,从而避免患者病情恶化,提供了更为动态和响应迅速的风险管理方案。
技术研发人员:谭寅虎,王洋,周秀玲,侯峣,李航,耿楠楠,王梦瑶,李长瑛,梁雪
技术所有人:长春中医药大学
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除