一种轻量级空间适配器增强的医学报告生成方法
本发明涉及一种针对医学报告生成的深度神经网络,尤其涉及一种轻量级空间适配器增强的医学报告生成方法。
背景技术:
1、医学图像对于患者的常规诊断和治疗至关重要。然而,尽管医生拥有丰富的知识和经验,医疗专业人员在分析大量医学图像并根据临床观察起草诊断报告时仍然耗时且容易出错。为了减轻医疗专业人员的负担并提高临床效率,实现自动化医学报告生成至关重要。该技术不仅简化了诊断过程,减少了医生的工作量,而且还提高了报告的一致性和准确性,从而更好地促进对患者的护理。
2、在深度学习领域,图像字幕是一项关键任务,它集成了计算机视觉和自然语言处理技术。自动生成图像的描述性字幕代表了人工智能的一个重要研究方向。图像字幕的目标是利用自然语言来描述图像,目的是基于对视觉内容的全面理解来生成有意义且语法正确的文本。医学报告的目标生成描述医学影响的详细报告,它是图像字幕的专业化任务。医疗报告的生成不仅需要生成更长的文本,还需要生成语术专业和准确的描述,这对于临床使用至关重要,传统的图像字幕生成方式已无法满足医学报告生成的要求。
3、对于医学跨媒体任务,模型捕获整体图像特征以及一些罕见但重要的细节至关重要。根据放射科医生的工作流程,当获得病人的医学图像时,他们首先检查全局区域以识别异常,并检查较小的且容易被忽视的局部区域,然后根据医学知识和经验起草精确的医学报告。然而,传统的预训练模型通常使用独立的transformer编码器来编码图像,这通常会导致空间细节的表示不足。此外,尽管自动医学报告生成和跨模式预训练模型取得了显着进步,但模型参数大小的增加的同时伴随着较小的性能提升阻碍了医学报告生成的进一步发展和应用。
4、综上所述,医学报告生成的难点在于如何在正确且有效地理解医学图像的内容,并准确地捕捉到图像中的异常区域,同时构建轻量级且高效的跨媒体医学报告生成框架,从而提升答案预测的准确性。
技术实现思路
1、本发明提供了一种针对医学报告生成的轻量级跨媒体方法。
2、本发明解决其技术问题所采用的技术方案如下:
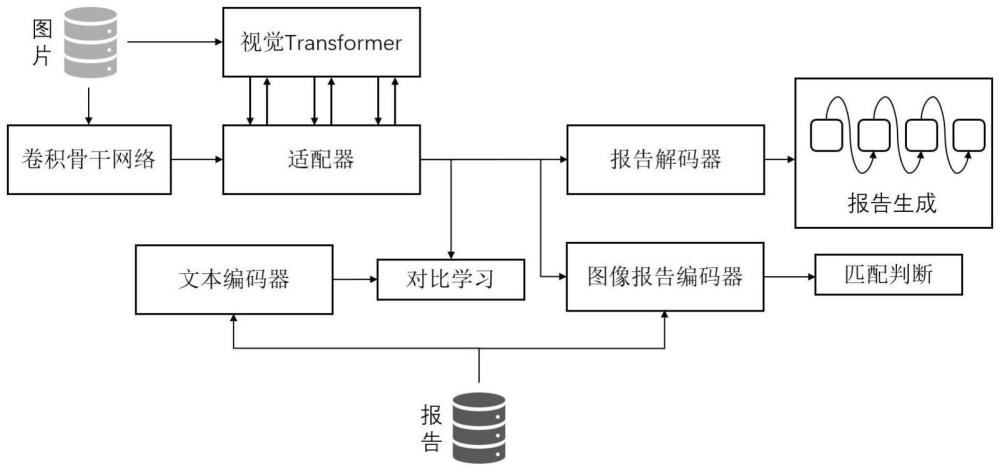
3、步骤(1)、构建全局视觉编码器,用于提取医学图像的全局特征,使得模型能更加准确地捕捉到图像中的一些异常区域。
4、步骤(2)、基于全局视觉编码器构建空间适配器,使得模型在较少的参数量下仍能保持优越的文本报告生成性能,利用空间适配器进行多轮迭代更新,以获取与报告生成最相关的视觉信息
5、步骤(3)、利用多种医学图像和对应的文本报告匹配任务构建跨媒体预训练模型,在对比学习的作用下通过更好地对齐复杂的视觉-文本关系,用于增强视觉与文本报告之间的融合。
6、步骤(4)、构建报告解码器,利用空间适配器输出的视觉特征,来生成医学图像诊断报告。
7、进一步的,步骤(1)所述的构建全局视觉编码器,用于提取医学图像的全局特征,以更准确的提取医学图像特征具体如下:
8、1-1.全局视觉编码器由一个补丁嵌入模块和n个块,每个块包含l个transformer编码层。输入的医学图像最初被输入到补丁嵌入模块中,其中图像被划分为大小为16×16的非重叠补丁。然后,每个补丁都会被展平并通过位置嵌入进行增强,以合并空间信息。随后补丁将经过l个transformer编码层,依次经过n个块以获得视觉特征。在整个过程中,特征的分辨率降低到原始医学图像的1/16,并引入一个标记来表示原始医学图像的全局特征。
9、步骤(2)所述的基于全局视觉编码器构建空间适配器,利用空间适配器进行多轮迭代更新,以获取与报告生成最相关的视觉信息,空间适配器包括空间注入器和特征提取器,具体如下:
10、2-1.对于空间注入器:将卷积骨干网络生成的特征图集成到全局视觉编码器的分支中。具体来说,从第i个特征提取器中提取的空间特征作为键和值,而从全局视觉编码器获得的特征作为查询。得到空间特征注入后的特征,如公式(1)所示:
11、
12、其中,i∈[0,1,2,3,4]表示全局视觉编码器中块的索引,而表示卷积骨干网络导出的初始特征,表示医学图像经过全局视觉编码器中补丁嵌入后的输出。ln(·)表示层归一化操作。crossattn(·)表示交叉注意力。λi是一个可学习的向量用来调节第i个块中注意力层的输出和输入特征之间的平衡。
13、2-2.对于特征提取器:将所得的全局相关特征输入到第i个块的编码层,输出特征下一个全局相关特征随后采用由交叉注意力层和前馈网络组成的特征提取器,以促进全局视觉编码器的隐藏层和空间注入器之间的交互;在交叉注意力层中,全局相关特征用作键和值输入,而空间细节特征用作查询输入;然后将空间细节特征通过前馈网络ffn进行处理以获得下一个空间细节特征如公式(2)(3)所示:
14、
15、其中,所得到的空间细节特征随后被用作后续空间注入器的输入。
16、2-3.在全局视觉编码器和空间适配器之间的进行n轮交互后,将包含空间细节特征和包含全局相关特征的融合视觉特征输入到报告解码器中;经过归一化以产生最终的视觉特征表示fv,如公式(4)所示:
17、
18、其中,norm(·)表示归一化操作。
19、步骤(3)具体如下:
20、3-1.为了增强医学图像i和对应的文本报告r的融合,首先计算图像i全局特征与文本报告r的相似度,如公式(5)(6)所示:
21、
22、其中,vcls、wcls分别指代医学图像i的全局特征和文本报告r的全局特征。
23、3-2.为了鼓励模型使匹配的图像报告对在表示空间中更接近,同时疏远不匹配的图像报告对。计算图像到报告的对比学习分数和报告到图像的对比学习分数,如公式(7)(8)所示:
24、
25、其中,fi2r(i)、fr2i(r)分别表示计算图像到报告的对比学习分数和报告到图像的对比学习分数,τ是可学习的温度参数。m表示批量大小,m表示批量中第m个样本。所计算的对比学习分数与其真值计算对比损失,如公式(9)所示:
26、
27、其中ce(·)表示交叉熵损失,yi2r(i)、yr2i(r)表示真值。
28、3-3.为了确定给定的图像报告对是匹配还是不匹配。使用包含双向自注意力层与前馈网络层以及用于增强视觉数据的集成,优化编码器以进行多模态信息处理的交叉注意机制相结合的transformer块组成的图像报告编码器,产生多模态嵌入特征。然后应用softmax函数来预测二类概率pirm,如公式(10)所示:
29、lirm=ce(yirm,pirm(i,r)) (公式10)
30、其中yirm表示真实标签的独热编码。
31、步骤(4)构建报告解码器,利用来自适配器增强空间视觉特征编码器的视觉特征,来生成医学图像诊断报告,具体如下:
32、4-1.为了促进从医学图像生成诊断报告,报告解码器采用了l层transformer解码层来构建自回归报告模型。解码器采用交叉注意机制来集成多模态嵌入,并使用序列一个开始标记启动生成过程。一个序列结束标记表示报告生成完成。报告解码器生成与所提供的医学图像相对应的报告。利用交叉熵损失引导模型通过自回归训练来最大化生成报告的可能性。通过前面时间步为t-1时生成的报告标记r1:t-1={r1,...,rt-1}输入到因果自注意力、交叉注意力和前馈层来预测时间步为t的报告标记如公式(11)(12)(13)所示:
33、hatt=ln(cmsa(r1:t-1)+r1:t-1) (公式11)
34、hca=ln(ca(hatt,fv)+hatt) (公式12)
35、
36、其中cmsa(·)、ca(·)分别表示因果多头自注意力和交叉注意力。推理阶段整个自回归生成过程如公式(14)所示:
37、
38、其中为时间步t之前所生成的词并作为生成是第t个词时的输入标记。
39、训练目标是在给定图像特征和目标报告的情况下最小化p(r|i)的负对数似然。通过计算预测标记和真实报告rt之间的交叉熵损失,可以促进语言模型的训练过程,训练目标如公式(15)所示:
40、
41、模型总体目标函数是上述三个预训练损失函数的组合,如公式(16)所示:
42、lall=lirc+lirm+llm (公式16)。
43、本发明有益效果如下:
44、本发明通过全局视觉编码器提取全局空间特征,使得模型能够提取完整的图像信息,在全局特征的基础上,通过空间适配器进一步更新视觉特征。将来自卷积骨干网络的局部空间特征与来自视觉transformer的全局特征通过空间适配器中的空间注入器和特征提取器进行多轮迭代更新,获取与报告生成最相关的视觉信息,实现更丰富和全面的特征表示,并通过报告解码器生成医学图像诊断报告。显著减少预训练模型的参数量,同时保持优越的报告生成性能。最后通过跨媒体预训练构建,更好地对齐图像和文本模态,处理医学图像中复杂的视觉-文本关系,以增强视觉与文本之间的融合。本发明能够在更少的可训练参数量下,得到与现有方法相当甚至更好的结果。
45、综上所述,本发明能够正确且有效地理解医学图像的内容,并准确地捕捉到图像中的异常区域,同时构建轻量级且高效的跨媒体医学报告生成框架,从而提升答案预测的准确性。
技术研发人员:余婷,卢旺文,章轲,储华
技术所有人:杭州师范大学
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除