语音识别方法、装置、设备及介质与流程
本公开涉及人工智能,尤其涉及大语言模型,更具体地,本公开提供了一种语音识别方法、装置、设备及介质。
背景技术:
1、语音识别技术(automatic speech recognition,asr)能够将输入的音频转换为文本。但目前的语音识别模型的识别能力不够理想,文本识别的准确率较低。
技术实现思路
1、有鉴于此,本公开提供了一种语音识别方法、装置、电子设备、介质以及程序产品。
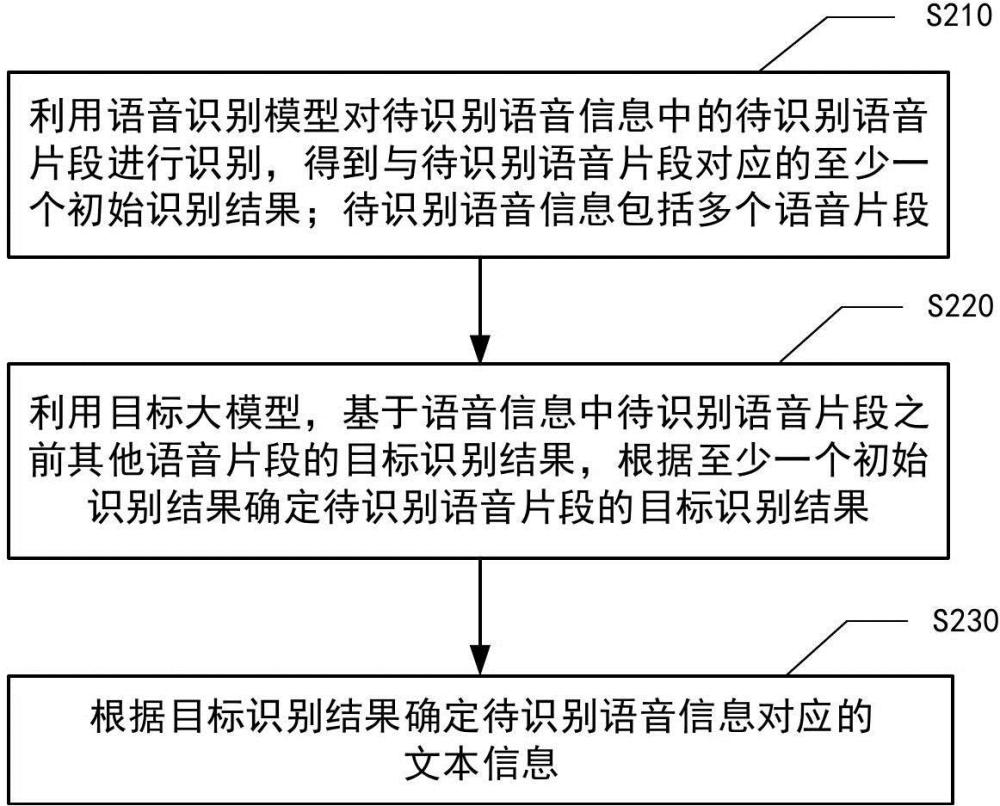
2、本公开的一个方面提供了一种语音识别方法,包括:利用语音识别模型对待识别语音信息中的待识别语音片段进行识别,得到与待识别语音片段对应的至少一个初始识别结果;待识别语音信息包括多个语音片段;利用目标大模型,基于待识别语音信息中待识别语音片段之前其他语音片段的目标识别结果,根据至少一个初始识别结果确定待识别语音片段的目标识别结果;根据目标识别结果确定待识别语音信息对应的文本信息。
3、根据本公开的实施例,利用目标大模型,基于待识别语音信息中待识别语音片段之前其他语音片段的目标识别结果,根据至少一个初始识别结果确定待识别语音片段的目标识别结果,包括:利用目标大模型,基于待识别语音信息中待识别语音片段之前其他语音片段的目标识别结果生成预测结果;根据预测结果确定至少一个初始识别结果的第一概率,以确定待识别语音片段的目标识别结果。
4、根据本公开的实施例,利用语音识别模型对待识别语音信息中的待识别语音片段进行识别,得到与待识别语音片段对应的至少一个初始识别结果,包括:利用语音识别模型对待识别语音信息中的待识别语音片段进行识别,得到与待识别语音片段对应的至少一个初始识别结果以及每个初始识别结果的第二概率;根据预测结果确定至少一个初始识别结果的第一概率,以确定待识别语音片段的目标识别结果,包括:根据至少一个初始识别结果的第一概率和第二概率,从至少一个初始识别结果中确定待识别语音片段的目标识别结果。
5、根据本公开的实施例,方法还包括:利用目标大模型,根据至少一个初始识别结果确定待识别语音片段的目标识别结果。
6、根据本公开的实施例,待识别语音片段包括时段标识,根据目标识别结果确定待识别语音信息对应的文本信息,包括:根据多个待识别语音片段对应的目标识别结果以及多个待识别语音片段的时段标识,得到待识别语音信息对应的文本信息。
7、根据本公开的实施例,目标大模型是通过以下方法得到的:获取样本语料,样本语料包括标注文本、语音片段样本的初始识别结果和/或处理语料,语音片段样本的初始识别结果是利用语音识别模型对语音片段样本进行识别得到的,处理语料是对语音片段的初始识别结果进行截取处理得到的;根据样本语料以及提示信息对初始大模型进行参数调整,得到目标大模型,目标大模型适用于样本语料对应的目标任务场景。
8、根据本公开的实施例,根据样本语料以及提示信息对初始大模型进行参数调整,得到目标大模型,包括:将样本语料和提示信息输入初始大模型; 初始大模型基于提示信息以及语音片段样本的初始识别结果和/或处理语料,得到针对语音片段样本的初始识别结果和/或处理语料的生成结果;基于生成结果和标注文本,对初始大模型的参数进行调整,得到目标大模型。
9、根据本公开的实施例,提示信息用于指示初始大模型在语音片段样本的初始识别结果和/或处理语料的指定位置之后进行内容生成。
10、根据本公开的实施例,标注文本包括第一时段标识,语音片段样本的初始识别结果包括第二时段标识,第一时段标识与第二时段标识相对应。
11、本公开的另一方面还提供了一种语音识别装置,包括:识别模块,用于利用语音识别模型对待识别语音信息中的待识别语音片段进行识别,得到与待识别语音片段对应的至少一个初始识别结果;待识别语音信息包括多个语音片段;识别结果确定模块,用于利用目标大模型,基于待识别语音信息中待识别语音片段之前其他语音片段的目标识别结果,根据至少一个初始识别结果确定待识别语音片段的目标识别结果;文本信息确定模块,用于根据目标识别结果确定待识别语音信息对应的文本信息。
12、本公开的另一方面提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,其中,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器执行上述方法。
13、本公开的另一方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述方法。
14、本公开的另一方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述方法。
15、应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种语音识别方法,包括:
2.根据权利要求1所述的方法,所述利用目标大模型,基于所述待识别语音信息中待识别语音片段之前其他语音片段的目标识别结果,根据所述至少一个初始识别结果确定所述待识别语音片段的目标识别结果,包括:
3.根据权利要求2所述的方法,所述利用语音识别模型对待识别语音信息中的待识别语音片段进行识别,得到与所述待识别语音片段对应的至少一个初始识别结果,包括:
4.根据权利要求1所述的方法,所述方法还包括:
5.根据权利要求1所述的方法,所述待识别语音片段包括时段标识,所述根据所述目标识别结果确定所述待识别语音信息对应的文本信息,包括:
6.根据权利要求1所述的方法,其中,所述目标大模型是通过以下方法得到的:
7.根据权利要求6所述的方法,其中,所述根据所述样本语料以及提示信息对初始大模型进行参数调整,得到所述目标大模型,包括:
8.根据权利要求6或7所述的方法,其中,所述提示信息用于指示所述初始大模型在所述语音片段样本的初始识别结果和/或处理语料的指定位置之后进行内容生成。
9.根据权利要求6所述的方法,其中,所述标注文本包括第一时段标识,所述语音片段样本的初始识别结果包括第二时段标识,所述第一时段标识与所述第二时段标识相对应。
10.一种语音识别装置,包括:
技术总结
本公开提供了一种语音识别方法,包括:利用语音识别模型对待识别语音信息中的待识别语音片段进行识别,得到与待识别语音片段对应的至少一个初始识别结果;待识别语音信息包括多个语音片段;利用目标大模型,基于待识别语音信息中待识别语音片段之前其他语音片段的目标识别结果,根据至少一个初始识别结果确定待识别语音片段的目标识别结果;根据目标识别结果确定待识别语音信息对应的文本信息。
技术研发人员:洪密,杨琳
受保护的技术使用者:联想(北京)有限公司
技术研发日:
技术公布日:2024/11/14
技术研发人员:洪密,杨琳
技术所有人:联想(北京)有限公司
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除