基于词向量的大语言模型问答方法、设备及存储介质与流程
本发明涉及神经网络应用领域,尤其涉及一种基于词向量的大语言模型问答方法、设备及存储介质。
背景技术:
1、大语言模型(large language model)是一种基于深度学习的自然语言处理技术,大语言模型通过对大量文本数据进行训练,学习到语言的结构和模式,从而能够生成、理解和处理自然语言。
2、大语言模型通常使用大规模的文本数据进行训练,构建了智能答复系统。由于大语言模型的训练成本较高且训练文本数据范围过大,需要投入的人力和物力与提升问答效果相比过大,现有大语言模型对于特定领域的需求无法满足。
3、因此,针对当前大语言模型直接从内部语料和网络框架更改的成本过大无法适应特定领域需求的技术问题,需要一种新的技术来解决当前问题。
技术实现思路
1、本发明的主要目的在于解决当前大语言模型直接从内部语料和网络框架更改的成本过大无法适应特定领域需求的技术问题。
2、本发明第一方面提供了一种基于词向量的大语言模型问答方法,所述基于词向量的大语言模型问答方法包括:
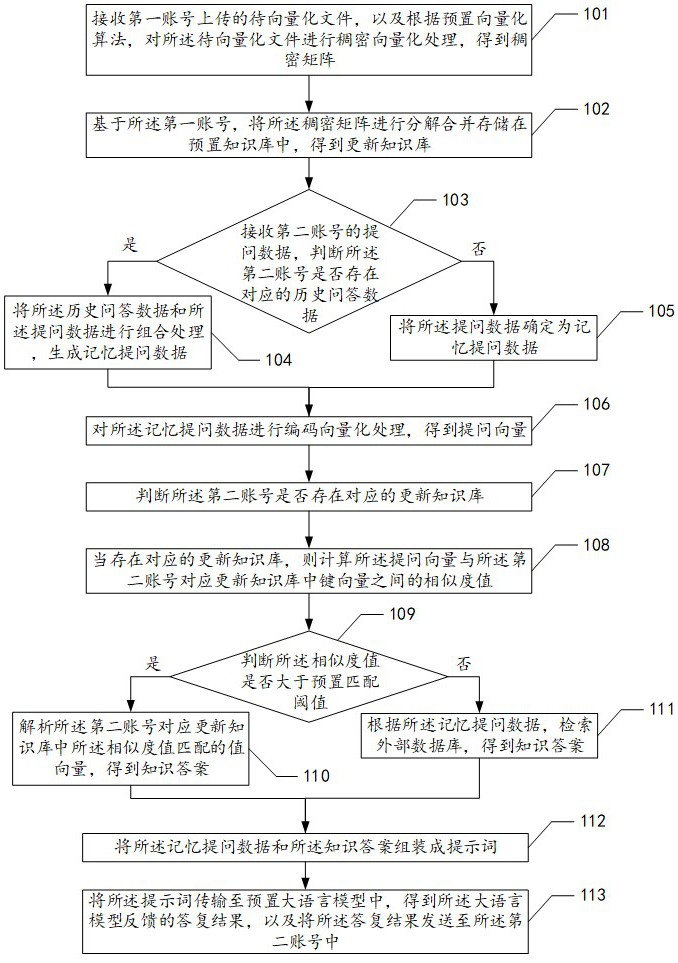
3、接收第一账号上传的待向量化文件,以及根据预置向量化算法,对所述待向量化文件进行稠密向量化处理,得到稠密矩阵;
4、基于所述第一账号,将所述稠密矩阵进行分解合并存储在预置知识库中,得到更新知识库;
5、接收第二账号的提问数据,判断所述第二账号是否存在对应的历史问答数据;
6、当存在对应的历史问答数据,则将所述历史问答数据和所述提问数据进行组合处理,生成记忆提问数据;
7、当不存在对应的历史问答数据,则将所述提问数据确定为记忆提问数据;
8、对所述记忆提问数据进行编码向量化处理,得到提问向量;
9、判断所述第二账号是否存在对应的更新知识库;
10、当存在对应的更新知识库,则计算所述提问向量与所述第二账号对应更新知识库中键向量之间的相似度值;
11、判断所述相似度值是否大于预置匹配阈值;
12、当大于预置匹配阈值,则解析所述第二账号对应更新知识库中所述相似度值匹配的值向量,得到知识答案;
13、当不大于预置匹配阈值,则根据所述记忆提问数据,检索外部数据库,得到知识答案;
14、将所述记忆提问数据和所述知识答案组装成提示词;
15、将所述提示词传输至预置大语言模型中,得到所述大语言模型反馈的答复结果,以及将所述答复结果发送至所述第二账号中。
16、可选的,在本发明第一方面的第一种实现方式中,所述计算所述提问向量与所述第二账号对应更新知识库中键向量之间的相似度值包括:
17、基于预置数据库索引,在所述第二账号对应更新知识库提取键向量;
18、计算出所述提问向量与所述键向量之间余弦相似值;
19、分析所述提问向量与所述键向量之间的交集元素数量,并分析所述提问向量与所述键向量之间的并集元素数量;
20、计算所述交集元素数量除所述并集元素数量的商,得到集合相似值;
21、将所述集合相似值和所述余弦相似值输入预置数值结合公式,得到相似度值。
22、可选的,在本发明第一方面的第二种实现方式中,所述将所述集合相似值和所述余弦相似值输入预置数值结合公式,得到相似度值包括:
23、z=min(x,y)+max(0,x-y),其中,z为相似度值,x为余弦相似度值,y为集合相似值。
24、可选的,在本发明第一方面的第三种实现方式中,所述判断所述第二账号是否存在对应的更新知识库包括:
25、判断预置服务内存中是否存在所述第二账号对应的更新知识库;
26、当预置服务内存中不存在所述第二账号对应的更新知识库,则判断预置云端服务器是否存在所述第二账号对应的更新知识库;
27、当预置云端服务器中存在所述第二账号对应的更新知识库,则将预置云端服务器中所述第二账号对应的更新知识库写入预置服务内存。
28、可选的,在本发明第一方面的第四种实现方式中,所述基于所述第一账号,将所述稠密矩阵进行分解合并存储在预置知识库中,得到更新知识库包括:
29、判断所述第一账号是否存在执行的存储任务;
30、当不存在执行的存储任务时,则根据所述待向量化文件的数值编码,对所述稠密矩阵进行问答矩阵分解,得到向量键值对,其中,所述向量键值对包括:问题向量和所述问题向量对应答案向量;
31、读取所述第一账号对应知识库的存储数据,以及将所述向量键值对与所述存储数据进行去重处理,得到更新存储数据;
32、基于所述更新存储数据,修改所述第一账号对应知识库的存储数据,生成更新知识库。
33、可选的,在本发明第一方面的第五种实现方式中,所述判断所述第二账号是否存在对应的历史问答数据包括:
34、判断所述第二账号在设置有效时长内是否存在对应的历史问答数据。
35、可选的,在本发明第一方面的第六种实现方式中,所述接收第一账号上传的待向量化文件包括:
36、接收第一账号上传的csv文件,其中,所述csv文件包括:问题字段、所述问题字段对应的答案字段。
37、可选的,在本发明第一方面的第七实现方式中,在所述根据所述记忆提问数据,检索外部数据库,得到知识答案之后,还包括:
38、发送所述提问数据对应的补充提醒信息至预置管理端口。
39、本发明第二方面提供了一种基于词向量的大语言模型问答设备,包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;所述至少一个处理器调用所述存储器中的所述指令,以使得所述基于词向量的大语言模型问答设备执行上述的基于词向量的大语言模型问答方法。
40、本发明的第三方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的基于词向量的大语言模型问答方法。
41、在本发明实施例中,通过用户账号上传知识库的向量化文件,对知识库进行调整使得每个用户账号有特定的分析问答结果,达成了不直接修改大语言模型的内部训练语料和内部网络框架即可将大语言模型适配特定领域效果,每个用户可以提问并快速准确的得到对应的完整响应结果,从而省去特定领域的常规问题答疑的人力资源支出,解决了当前大语言模型直接从内部语料和网络框架更改的成本过大无法适应特定领域需求的技术问题。
技术特征:
1.一种基于词向量的大语言模型问答方法,其特征在于,包括步骤:
2.根据权利要求1所述的基于词向量的大语言模型问答方法,其特征在于,所述计算所述提问向量与所述第二账号对应更新知识库中键向量之间的相似度值包括:
3.根据权利要求2所述的基于词向量的大语言模型问答方法,其特征在于,所述将所述集合相似值和所述余弦相似值输入预置数值结合公式,得到相似度值包括:
4.根据权利要求1所述的基于词向量的大语言模型问答方法,其特征在于,所述判断所述第二账号是否存在对应的更新知识库包括:
5.根据权利要求1所述的基于词向量的大语言模型问答方法,其特征在于,所述基于所述第一账号,将所述稠密矩阵进行分解合并存储在预置知识库中,得到更新知识库包括:
6.根据权利要求1所述的基于词向量的大语言模型问答方法,其特征在于,所述判断所述第二账号是否存在对应的历史问答数据包括:
7.根据权利要求1所述的基于词向量的大语言模型问答方法,其特征在于,所述接收第一账号上传的待向量化文件包括:
8.根据权利要求1所述的基于词向量的大语言模型问答方法,其特征在于,在所述根据所述记忆提问数据,检索外部数据库,得到知识答案之后,还包括:
9.一种基于词向量的大语言模型问答设备,其特征在于,所述基于词向量的大语言模型问答设备包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;
10.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-8中任一项所述的基于词向量的大语言模型问答方法。
技术总结
本发明涉及神经网络应用领域,公开了一种基于词向量的大语言模型问答方法、设备及存储介质。该方法包括:基于第一账号,将稠密矩阵进行分解合并存储在预置知识库中,得到更新知识库;将历史问答数据和提问数据进行组合处理,生成记忆提问数据;对记忆提问数据进行编码向量化处理,得到提问向量;计算提问向量与第二账号对应更新知识库中键向量之间的相似度值;解析第二账号对应更新知识库中相似度值匹配的值向量,得到知识答案;将提示词传输至大语言模型中,得到大语言模型反馈的答复结果,以及将答复结果发送至第二账号中。在本发明实施例中,不需要修改大语言模型的内部训练语料和内部网络框架即可将大语言模型适配特定领域。
技术研发人员:徐约可,谢国斌,马明,李环良
受保护的技术使用者:深圳大道云科技有限公司
技术研发日:
技术公布日:2024/11/14
技术研发人员:徐约可,谢国斌,马明,李环良
技术所有人:深圳大道云科技有限公司
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除