合成数据生成的制作方法
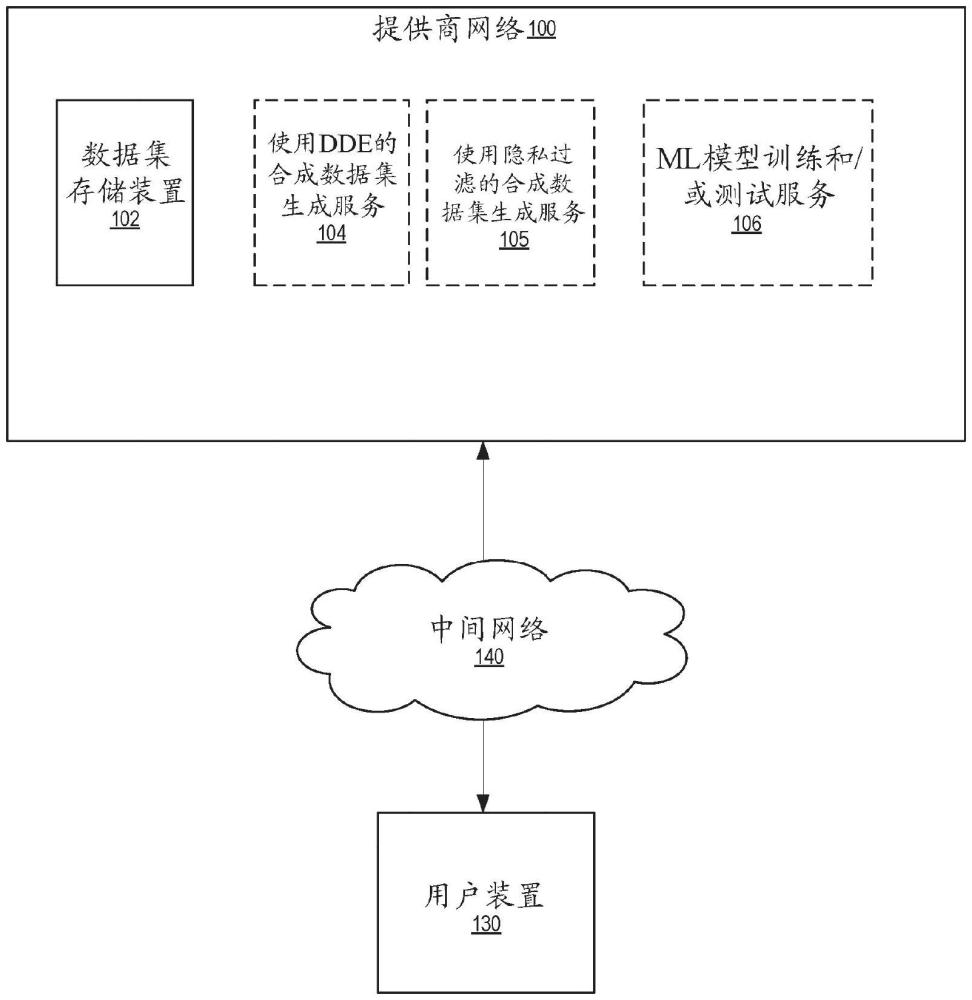
背景技术:
1、生物信息学研究的特征在于大数据集,由于关于样本大小的实际和成本相关的限制,这些数据集通常维度较高、但样本大小较低。当应用数据饥渴的机器学习算法时,这可能导致各种挑战——特别是在类不平衡的情况下,诸如在要分类的一些类别比其他类别具有明显更少的数据点的情况下。具有较少样本的少数类通常也是感兴趣的类。
技术实现思路
技术特征:
1.一种计算机实现的方法,其包括:
2.如权利要求2所述的计算机实现的方法,所述一个或多个请求包括以下一项或多项:要从所述第一数据集排除什么特征的标识、所述第一数据集的位置的标识、所述第一数据集本身、要生成的合成数据点的数量、存储所述合成数据集的地方的位置的标识、要考虑的数据点对的数量、邻域大小或用于最小化可标识性的度量的指示。
3.如权利要求1-2中任一项所述的计算机实现的方法,其中通过在所述第一数据集的最近邻居对之间沿着连接经初始化的数据点及其对应对的线选择合成数据点的集合同时最大化局部概率分布来根据所述请求生成所述合成数据集包括:
4.如权利要求1所述的计算机实现的方法,其中所述一个或多个请求指示当生成所述数据集的所述合成数据点时应当考虑隐私,并且通过在所述第一数据集的数据点对之间沿着连接所述数据点对的线选择合成数据点的集合,同时对局部概率分布的可能值进行采样来根据所述请求生成所述合成数据集还包括:
5.如权利要求4所述的计算机实现的方法,其中隐私符合健康保险携带和责任法案(hipaa)的方面。
6.如权利要求4所述的计算机实现的方法,其中隐私至少符合通用数据保护条例(gdpr)第29条的方面。
7.如权利要求4所述的计算机实现的方法,其中隐私确保所述合成数据集中的给定数据点不可标识。
8.如权利要求1-7中任一项所述的计算机实现的方法,其中所述第一数据集和合成数据集具有高维度。
9.如权利要求1-8中任一项所述的计算机实现的方法,其中所述投影是一维投影。
10.如权利要求1-9中任一项所述的计算机实现的方法,其中所估计的概率分布使用核密度估计来执行。
11.如权利要求1至10中任一项所述的计算机实现的方法,其还包括:
12.一种系统,其包括:
13.如权利要求12所述的系统,其中所述一个或多个请求指示当生成所述数据集的所述合成数据点时应当考虑隐私,并且通过在所述第一数据集的数据点对之间沿着连接所述数据点对的线选择合成数据点的集合,同时对局部概率分布的可能值进行采样来根据所述请求生成所述合成数据集还包括:
14.如权利要求12所述的系统,其中隐私确保所述合成数据集中的给定数据点不可标识。
15.如权利要求12-14中任一项所述的系统,还包括用于测试所述合成数据集的测试服务。
技术总结
描述了用于生成合成数据的技术。示例性方法包括:接收基于第一数据集生成合成数据的一个或多个请求;通过在所述第一数据集的数据点对之间沿着连接所述数据点对的线选择合成数据点的集合,同时对局部概率分布的可能值进行采样,根据所述请求生成所述合成数据集;以及如所述请求配置那样提供所述合成数据集。
技术研发人员:T·马德尔,M·J·霍华德
受保护的技术使用者:亚马逊技术股份有限公司
技术研发日:
技术公布日:2024/11/14
技术研发人员:T·马德尔,M·J·霍华德
技术所有人:亚马逊技术股份有限公司
备 注:该技术已申请专利,仅供学习研究,如用于商业用途,请联系技术所有人。
声 明 :此信息收集于网络,如果你是此专利的发明人不想本网站收录此信息请联系我们,我们会在第一时间删除